Abstract
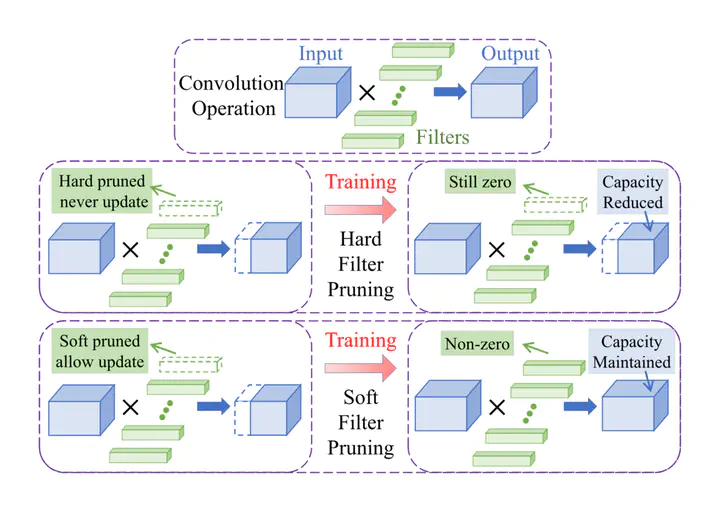
This paper proposed a Soft Filter Pruning (SFP) method to accelerate the inference procedure of deep Convolutional Neural Networks (CNNs). Specifically, the proposed SFP enables the pruned filters to be updated when training the model after pruning. SFP has two advantages over previous works: (1) Larger model capacity. Updating previously pruned filters provides our approach with larger optimization space than fixing the filters to zero. Therefore, the network trained by our method has a larger model capacity to learn from the training data. (2) Less dependence on the pre-trained model. Large capacity enables SFP to train from scratch and prune the model simultaneously. In contrast, previous filter pruning methods should be conducted on the basis of the pre-trained model to guarantee their performance. Empirically, SFP from scratch outperforms the previous filter pruning methods. Moreover, our approach has been demonstrated effective for many advanced CNN architectures. Notably, on ILSCRC-2012, SFP reduces more than 42% FLOPs on ResNet-101 with even 0.2% top-5 accuracy improvement, which has advanced the state-of-the-art.