Abstract
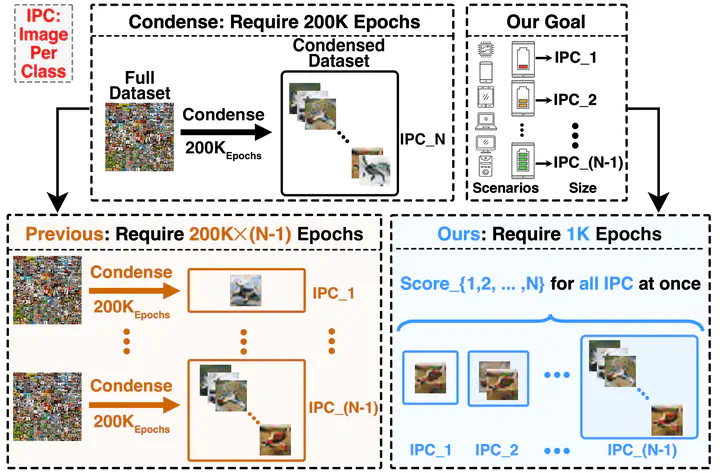
Dataset condensation is a crucial tool for enhancing training efficiency by reducing the size of the training dataset, particularly in on-device scenarios. However, these scenarios have two significant challenges: 1) the varying computational resources available on the devices require a dataset size different from the pre-defined condensed dataset, and 2) the limited computational resources often preclude the possibility of conducting additional condensation processes. We introduce You Only Condense Once (YOCO) to overcome these limitations. YOCO offers two key advantages: 1) it can flexibly resize the dataset based on two discovered rules, Low LBPE Score and Balanced Construction, to fit varying computational constraints, and 2) it eliminates the need for extra condensation processes, which can be computationally prohibitive. Experiments validate our findings on networks including ConvNet, ResNet and DenseNet, and datasets including CIFAR-10, CIFAR-100 and ImageNet. For example, our YOCO surpassed various dataset condensation and dataset pruning methods on CIFAR-10 with ten Images Per Class (IPC), achieving 6.95-9.91% and 6.57-24.33% accuracy gains, respectively.