Abstract
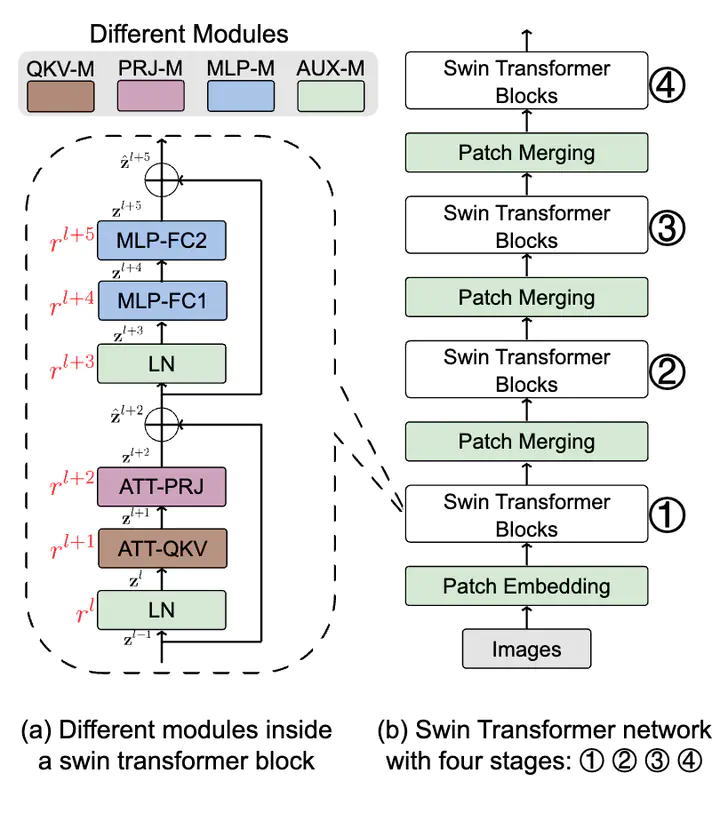
Hierarchical vision transformers (ViTs) have two advantages over conventional ViTs. First, hierarchical ViTs achieve linear computational complexity with respect to image size by local self-attention. Second, hierarchical ViTs create hierarchical feature maps by merging image patches in deeper layers for dense prediction. However, existing pruning methods ignore the unique properties of hierarchical ViTs and use the magnitude value as the weight importance. This approach leads to two main drawbacks. First, the “local” attention weights are compared at a “global” level, which may cause some “locally” important weights to be pruned due to their relatively small magnitude “globally”. The second issue with magnitude pruning is that it fails to consider the distinct weight distributions of the network, which are essential for extracting coarse to fine-grained features at various hierarchical levels. To solve the aforementioned issues, we have developed a Data-independent Module-Aware Pruning method (DIMAP) to compress hierarchical ViTs. To ensure that “local” attention weights at different hierarchical levels are compared fairly in terms of their contribution, we treat them as a module and examine their contribution by analyzing their information distortion. Furthermore, we introduce a novel weight metric that is solely based on weights and does not require input images, thereby eliminating the dependence on the patch merging process. Our method validates its usefulness and strengths on Swin Transformers of different sizes on ImageNet-1k classification. Notably, the top-5 accuracy drop is only 0.07% when we remove 52.5% FLOPs and 52.7% parameters of Swin-B. When we reduce 33.2% FLOPs and 33.2% parameters of Swin-S, we can even achieve a 0.8% higher relative top-5 accuracy than the original model. Code is available at: https://github.com/he-y/Data-independent-Module-Aware-Pruning