Abstract
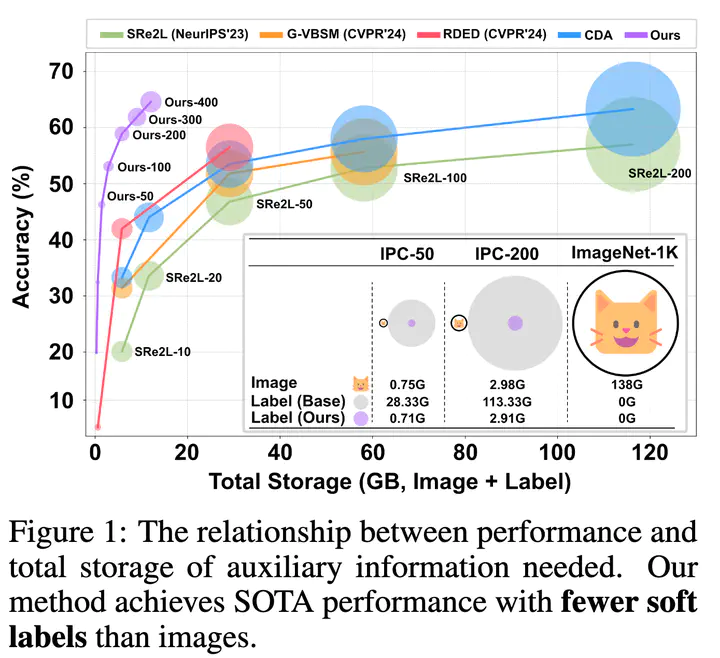
In ImageNet-condensation, the storage for auxiliary soft labels exceeds that of the condensed dataset by over 30 times. However, are large-scale soft labels necessary for large-scale dataset distillation? In this paper, we first discover that the high within-class similarity in condensed datasets necessitates the use of large-scale soft labels. This high within-class similarity can be attributed to the fact that previous methods use samples from different classes to construct a single batch for batch normalization (BN) matching. To reduce the within-class similarity, we introduce class-wise supervision during the image synthesizing process by batching the samples within classes, instead of across classes. As a result, we can increase within-class diversity and reduce the size of required soft labels. A key benefit of improved image diversity is that soft label compression can be achieved through simple random pruning, eliminating the need for complex rule-based strategies. Experiments validate our discoveries. For example, when condensing ImageNet-1K to 200 images per class, our approach compresses the required soft labels from 113 GB to 2.8 GB (40x compression) with a 2.6% performance gain.