Swift Cross-Dataset Pruning: Enhancing Fine-Tuning Efficiency in Natural Language Understanding
Abstract
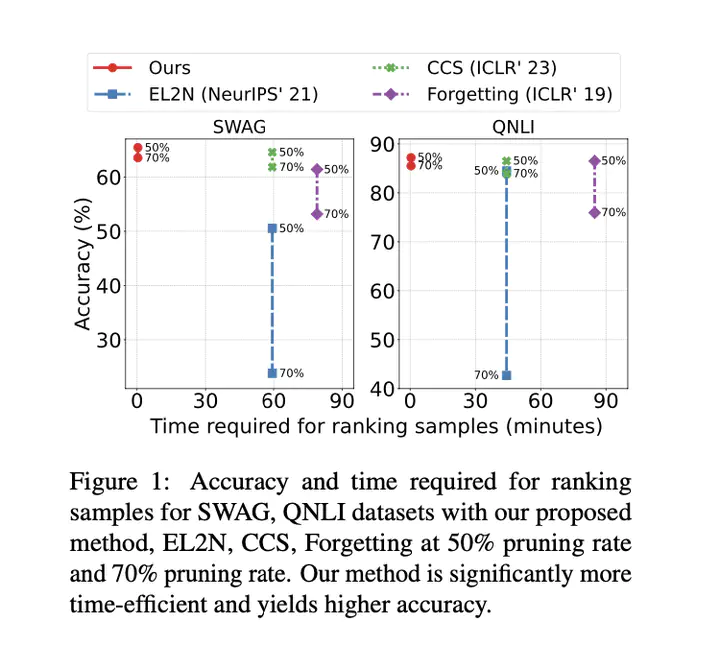
Dataset pruning aims to select a subset of a dataset for efficient model training. While data efficiency in natural language processing has primarily focused on within-corpus scenarios during model pre-training, efficient dataset pruning for task-specific fine-tuning across diverse datasets remains challenging due to variability in dataset sizes, data distributions, class imbalance and label spaces. Current cross-dataset pruning techniques for fine-tuning often rely on computationally expensive sample ranking processes, typically requiring full dataset training or reference models. We address this gap by proposing Swift Cross-Dataset Pruning (SCDP). Specifically, our approach uses TF-IDF embeddings with geometric median to rapidly evaluate sample importance. We then apply dataset size-adaptive pruning to ensure diversity: for smaller datasets, we retain samples far from the geometric median, while for larger ones, we employ distance-based stratified pruning. Experimental results on six diverse datasets demonstrate the effectiveness of our method, spanning various tasks and scales while significantly reducing computational resources.