Soft Label Pruning and Quantization for Large-Scale Dataset Distillation
Abstract
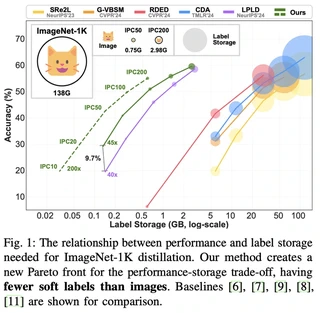
Large-scale dataset distillation requires storing auxiliary soft labels that can be 30-40x (ImageNet-1K) or 200x (ImageNet-21K) larger than the condensed images, undermining the goal of dataset compression. We identify two fundamental issues necessitating such extensive labels: (1) insufficient image diversity, where high within-class similarity in synthetic images requires extensive augmentation, and (2) insufficient supervision diversity, where limited variety in supervisory signals during training leads to performance degradation at high compression rates. To address these challenges, we propose Label Pruning and Quantization for Large-scale Distillation (LPQLD). We enhance image diversity via class-wise batching and BN supervision during synthesis. For supervision diversity, we introduce Label Pruning with Dynamic Knowledge Reuse to enhance label-per-augmentation diversity, and Label Quantization with Calibrated Student-Teacher Alignment to enhance augmentation-per-image diversity. Our approach reduces soft label storage by 78x on ImageNet-1K and 500x on ImageNet-21K while improving accuracy by up to 7.2% and 2.8%, respectively. Extensive experiments validate the superiority of LPQLD across different network architectures and other dataset distillation methods.
Type
Publication
IEEE Transactions on Pattern Analysis and Machine Intelligence (Early Access)
Authors

Authors
Senior Scientist
I am a Senior Scientist at the Centre for Frontier AI Research (CFAR), Agency for Science, Technology and Research (A*STAR), Singapore. I also serve as an Adjunct Assistant Professor at the National University of Singapore (NUS).
I received my Ph.D. from the University of Technology Sydney (UTS) under the supervision of Prof. Yi Yang.